

Retrospective: Blogator v1.0
Table of Contents
This post highlights some of the aspects which I either found interesting, could be improved upon, or turned out to be a problem during development of the first version of the Blogator static site generator. In other words: this is just a curated selection of topics, not a report.
As for the result: you are looking at it. The entire bloging section of this site was generated with Blogator. 👍
1. Design background
Just to set the stage a little bit and bring some context, the hard requirements were set as follows:
- As few dependencies as possible. Don't want to run this one day and find out it's broken because a 3rd party library/framework has a new API or is just not available anymore.
- No Javascript in the output. It needs to be able to display everything and have working links when JS is disabled in the browser.
- HTML-based for source material. I.e. all articles to be published can be written in plain HTML allowing a maximum of granular flexibility in their formatting.
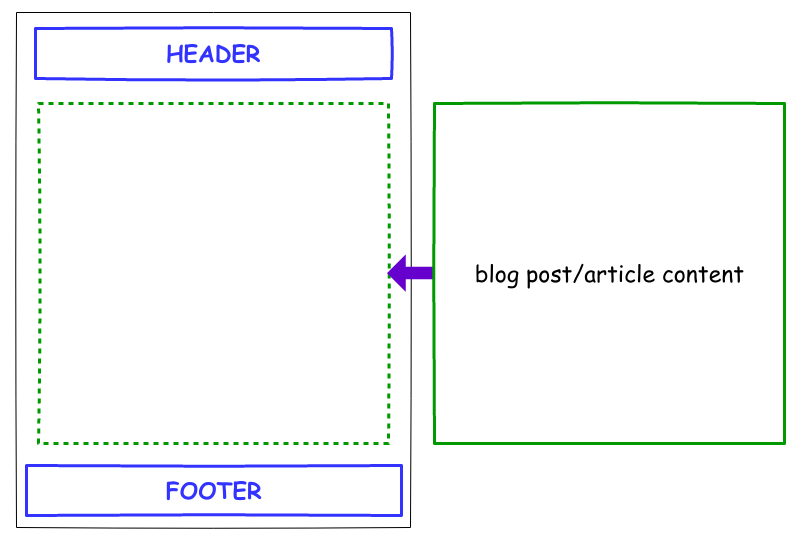
At first, just collating the header/footer parts of the site to each of the articles seemed like a viable path to take. A simple page listing all articles as a list of hyperlinks could be generated as a 'master index' of sorts. But this raises a couple of issues:
- Navigation: How to go to the previous/next article without having to manually add that part in for each article.
- Expandability: How to allow navigation by arbitrary types in the future without huge rewrites of the code (authors, date, categories, ...).
Both issues are solved by just using templates in which key parts of the articles (title, date, content, navigation, etc...) can be inserted on a per-article basis.
Eventually, after some development time, I settled with the following template files:
- Landing page: or the start page of the blog,
- Post: to display each of the articles,
- Index page: lists the articles as customisable hyperlinked divs,
- Index list page: for category listings (such as year, author, tags) that links to a sub index for each,
- Index entry: or how the hyperlinked div for the article will look in the indices.
...leading to an I/O file/folder outline of:
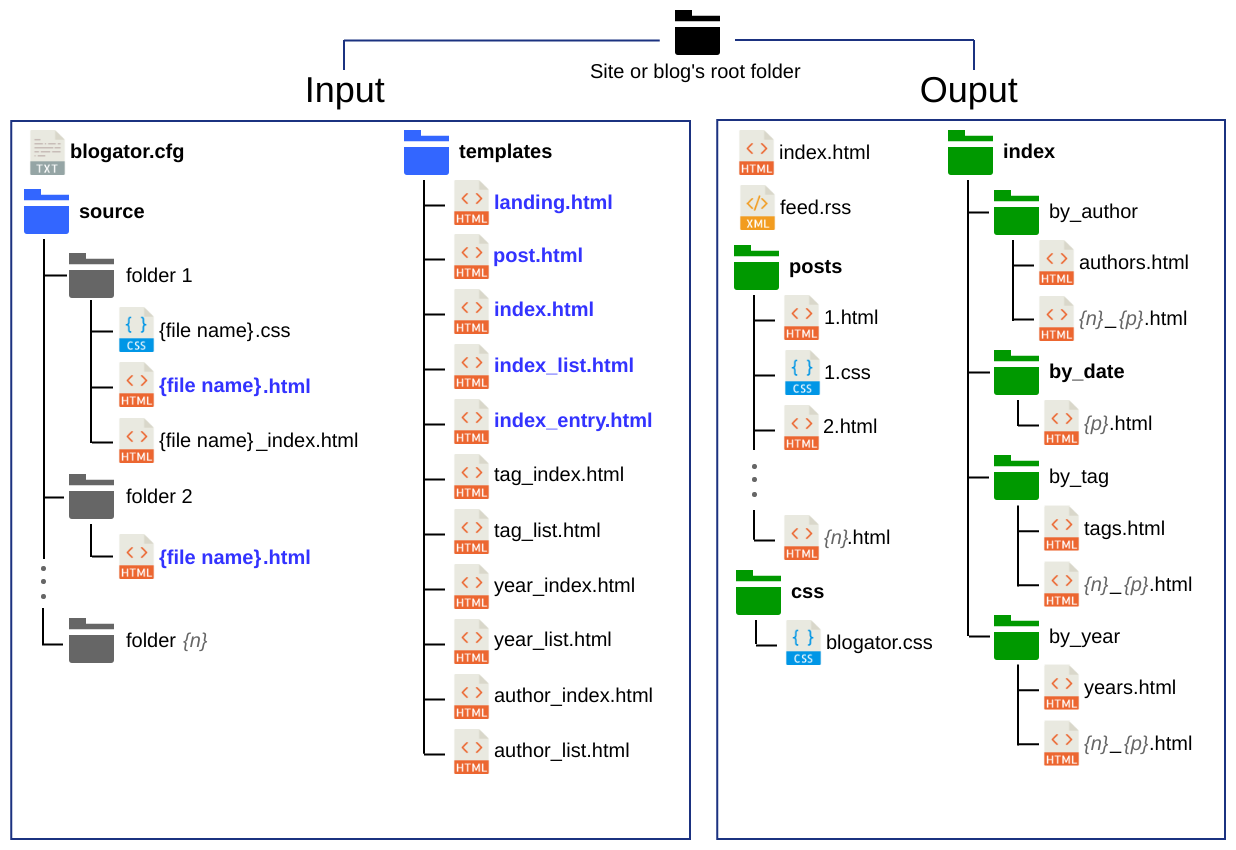
Extra index and index list templates can be added as "overrides" optionally allowing some flexibility of the design on a per-category basis (e.g.: 'tag_list.html', 'tag_index.html', etc...).
2. Parsing: regular expressions or string find?

In order to help create a sort of 'master' index of all the articles some information from them need to be parsed.
Aside from the obvious fields (title, date stamp), others are needed for categorising the articles (tags and authors) as well as pointing out what text can be used as summary for the article entries in any indices created.
Parsing the key texts need not be difficult: a plain text-search that finds the encompassing html tags (i.e. getting the start-end indices within the string) and lifts any text found between them should do the trick assuming the source HTML is correct. For example:
std::string from = "class=\"title\">";
std::string to = "</";
std::string content;
auto i_begin = str.find( from );
if( i_begin != std::string::npos ) {
auto range_begin = i_begin + from.length();
auto i_end = str.find( to, range_begin );
if( i_end != std::string::npos ) {
auto range_end = i_end - ( i_begin + from.length() );
content = str.substr( range_begin, range_end );
}
}
For field types where there could be multiple declarations, such as 'tag', 'author' and 'summary', the code can be adapted to run until the end of the source HTML text whilst gathering the field contents as it finds them.
Another technique for field extraction is to use regular expressions. It does have significant drawback though as the performance hit is on the high side.
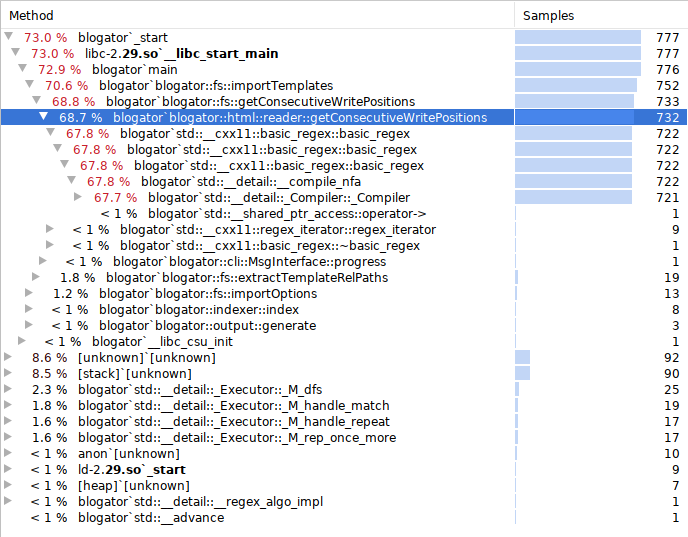
Running perf confirms it (fig.4). The bulk of the load happens during the import of the templates where all insert positions are found using regular expressions
This is fine as there is a finite number of templates (5-11 max currently in v1.0b) with a finite number of insertion points in each.
Using the same method for parsing the articles whose count and lengths are not bound is not scalable (side-note: the slowest part of regular expressions is the compilation).
This is where markdown-based static generators are at a considerable advantage as parsing articles written in that format is easier in comparison (simpler syntax). HTML can cause many issues especially in the cases where formatting tags are mismatched, unclosed or malformed.
3. Sanitising the summary fields
Speaking of issues... What if there are hyperlinks inside the content to be used within another hyperlink? i.e. a nested hyperlink. This is what happened with the summaries.
<a href="..">
<div>
<div class=summary>
<a href=".."></a>
</div>
</div>
</a>
In order to avoid that problem, all summaries must be checked for any hyperlinks as they are cached. Any found need to have their html <a ..></a> tags removed.
4. Adapting relative paths in from source HTML
Here's the problem: a path is used inside a post pointing to a specific file inside the website directory sub-structure. The source post is located at:
~/website/source/post1/post.html
The file being referenced by the path is:
~/website/img/photos/file.jpg
The post, once processed by Blogator, will be located at:
~/website/posts/1.html
There are 3 different approaches one can take to make sure the path is correctly pointing to the target file in the output post:
- use an absolute path based on the root of the site:
/img/photos/file.jpg, - use a relative path based on where the generated post will be at:
../img/photos/file.jpg, - use a relative path based on where the source is at (
../../img/photos/file.jpg) but then adapt it during output generation (../img/photos/file.jpg).
Option 1 doesn't require any particular processing. Option 2 puts the responsibility of working out the output's relative path on the operator which can lead to errors. Finally, option 3 can allow relative links but without the potential errors introduced by the manual conversion from option 2. Blogator thus got to support options 1 and 3.
Adapting relative paths is broken down into a number of steps:
- Finding & Extracting: The source HTML is loaded into memory and searched for any relative paths. Whenever one is found the line and character start/end positions is cached along with the relative path.
- Adapting: The path is adapted using C++'s
std::filesystem::functionality.auto source_abs = ( source_file.parent_path() / rel_path ).lexically_normal(); auto target_rel = source_abs.lexically_relative( target_file.parent_path() ); - Inserting: During write to the output, when a cached start/end position is encountered, the adapted relative path is inserted instead of the original one.
- Checking: All cached relative paths are checked by looking if the target exists in the filesystem. If it doesn't then a message is pushed to the terminal display to inform the operator of that issue.
5. Forgetting character encoding

Ooh boy... This is what happens when the research & design is rushed. Not having come across this particular problem before allowed some uninformed assumptions to be baked into the project. These assumptions boiled down to one really bad one: "std::string should be fine handling HTML stuff."
Turns out: not really. Having come across the rather excellent post by Joel Spolsky it suddenly dawned on me halfway in the implementation that I had overlooked a rather large and important topic...
Converting and doing everything using wide characters internally inside the software and then reconverting to single-byte char on the output when you can is a better approach for cross-language and platform compatibility. The only downside to that aside from the conversion overhead is the fact that it doubles the memory requirement of any cached string (1 byte → 2 bytes per character).
Oh well, live and learn. It can be implemented for version 2.0 during the re-write if it gets to that. For the moment UTF-8 on the target platform (Linux) works fine which is what was originally needed.
6. Configuration
6.1 CLI arguments
In order to pass run-time arguments to Blogator a little backend magic is required. Using GNU's getopt or argp was considered but it adds an external dependency (albeit included in Linux distros). Since the number of arguments to be parsed via the command line is limited, implementing a small custom parser isn't much work and leads to a more portable solution.
All that is needed really is:
- help option to show the available command line options and the version of the software,
- debug option to show extra messages to help sort out errors,
- path of site when different than the current directory where Blogator is run from,
- and a way to create a default configuration file.
The implementation just uses a map of of the argument flags and their respective enums to check the flags given via the command line by the operator. Then a series of conditional statements making use of the enums controls the activation of the required functionalities and arguments passed (blogator::cli::ArgParser).
6.2 Configuration file
As the CLI interface options can easily get cluttered, any of the more website-specific options are pushed on a configuration file instead.
In the implementation, each line is processed using regular expressions that identify if the format is:
- A comment. e.g.:
//This is a comment line - An option with a boolean variable. e.g.:
build-future = false; - An option with an integer variable. e.g.:
items-per-page = 10; - An option with a string variable. e.g.:
breadcrumb-landing-page = "Home"; - An option with an array of string variables. e.g.:
landing-featured = [ "post_1/post.html", "post_4/post.html" ];
Anything else (or badly formatted line) is identified as an unreadable line to the operator.
For each options lifted from the configuration file, the option's name and its variable(s) are stored in a lookup map along with the line number (for error reporting purposes) and an enum describing the value type.

After that it's just a question of iterating over all the supported keys and checking them against the lookup map. If there's a match then value conversion based on the type is done and the result stored in the blogator::dto::Options structure.
7. Terminal display
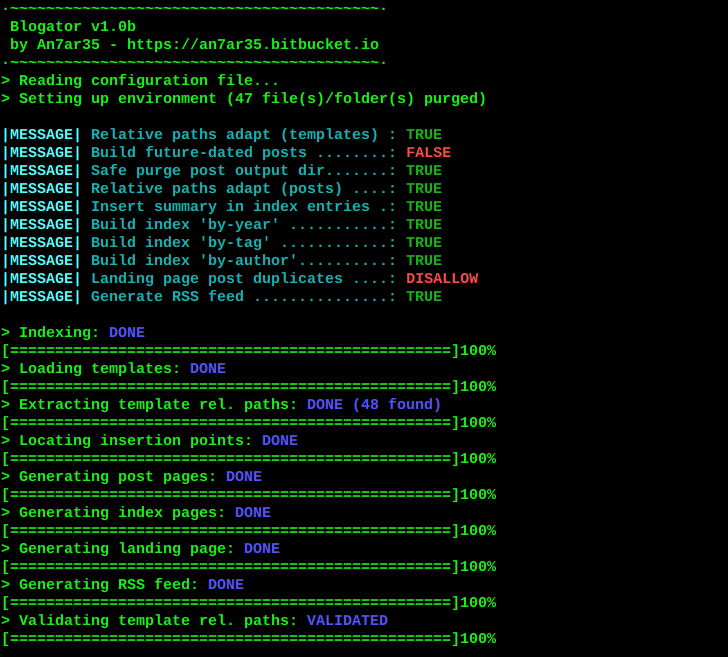
A progress bar is decidedly a better way to give the operator (or 'user') some feedback on the progress of a process. Messages disembodied from the originating context, usually coming from deep within the bowls of the code, are of little use unless they give actionable information. Thus, a nice graphic representation of the amount left to do is preferred here. But then, when things do go wrong, messages are also needed.
This is the quandary that led to a buffered message approach. One of the issues of displaying ASCII based graphics in the terminal is that writing messages around it requires keeping track of the number of lines to move the cursor back and forth for either (a) updating the progress bar or (b) adding message lines after where the last one that was writen. I.e.: it sucks.
[========================= ] 50%
message 1 ....
message 2 ....
message 3 ....
Of course I could be using nCurse if not for that pesky little little requirement of keeping dependencies to the strict minimum. So a little out-of-the-box thinking is required...
7.1 Progress bars
Terminal progress bars in a basic form essentially write an entire line for the current progress state then return the cursor at the beginning of said line for the next one to be written over it.
The only thing that differs from most implementations of this is that the terminal cursor resets back 1 line above the bar in order to display a progress state as well as the graphical representation of said state. I.e.: it tells the operator what particular section or file is being processed during each iteration of the progress.

7.2 Redirecting the error stream to the message buffer
In C++ the lifecycle of resources is managed with RAII which is freakin' awesome. This means that things created during the construction of an object are auto-magically cleared out of memory on destruction. That is so long as we keep to the reasonably recent C++ standards (C++11 or above) and not some university level bastardisation of C and C++ (a.k.a. "C but with objects" 😒). It also means that we can divert an output stream on startup and put it back in place at the end automatically.
In our case, the error stream std::cerr is redirected to a std::stringstream.
This is used to catch anything sent to the std::cerr buffer in order to not mess up the display whilst progress and other messages are being outputted. The custom string stream buffer is flushed out to the display at the end of the program's lifecycle.
class MsgDisplay {
public:
MsgDisplay() :
_old_cerr_buffer( std::cerr.rdbuf( _err_buffer.rdbuf() ) )
{};
~MsgDisplay() {
auto cerrors = _err_buffer.str();
if( !cerrors.empty() )
std::cout << _err_buffer.str() << std::endl;
std::cerr.rdbuf( _old_cerr_buffer );
}
private:
std::stringstream _err_buffer;
std::streambuf *_old_cerr_buffer;
};
One assumption (a rather big one!) is that the errors sent to that stream will be quite small in number. A potential issue with this is the case of an error loop that feeds the buffer with the same error over and over again. Good methodical error control where exceptions are caught and dealt with appropriately (particularly in loops) is always judicious.
As the program is not massive nor multi-threaded I absconded from constantly keeping check on that buffer. That being said if I had to do it all over again I would either have put the whole display on its own separate thread and added a monitoring loop or just redirected the stream to a log file (something that I might very well do in a future update).
7.3 Coloured Output
Colouring text output in the terminal can be done with ANSI escape codes. In itself it is neither particularly challenging nor novel.
Inserting the escape codes can be a bit fidly and the code inside the printing methods can soon become littered with them. Thus a more standardised approach was devised using template meta-programing. The trick here was to allow both colour and decorations (e.g.: underline) to be added cleanly and clearly. So with a bit of enum and recursion magic we get this:
enum class FGColour {
BLACK = 30, RED = 31, GREEN = 32, YELLOW = 33, BLUE = 34, MAGENTA = 35, CYAN = 36, WHITE = 37
};
enum class Decoration {
BOLD = 1, FAINT = 2, ITALIC = 3, UNDERLINE = 4
};
template<FGColour colour>
void format_( std::stringstream &ss ) {}; //Stops recursion
template<FGColour colour, Decoration head, Decoration ...tail>
void format_( std::stringstream &ss )
{
ss << ';' << static_cast<int>( head );
format_<colour, tail...>( ss );
};
template<FGColour colour, Decoration ...args>
std::string format( const std::string &str )
{
std::stringstream ss;
ss << "\33[" << static_cast<int>( colour );
format_<colour, args...>( ss );
ss << "m" << str << "\033[0m";
return ss.str();
};
Using this approach also allows for chainning decorations to the string with minimal code duplication and a clean method interface. For example:
format<FGColour::RED, Decoration::BOLD, Decoration::UNDERLINE>( "some string to format" );
The full implementation is available in EADlib's CLI namespace (eadlib::cli::).
8. Final thoughts
Originally I created Blogator to help generate posts for both my little site and a local association's who I offered my services to. As it enabled me to do both to satisfaction, it can be put down as a success in that sense.
But, as with most things, there is both good and bad. With better research & design at the beginning (given more time), implementation and future maintainability could've been much better. In the end it is a viable product with its own flaws but it also was a great way to explore and learn.
The bad
- Still many areas where improvement could be made especially in the code architecture (rushed design stage = bad!).
- The whole character code issue puts a damper on UTF-16.
The good
- Runs pretty darn fast to compile this site on an Ivy bridge i7 3770K from 2012.
- At just under 900kB compiled, Blogator could easily be stored on a double density floppy which is more than can be said about some other static site generator solutions...
- There are no dependencies aside from C++ Standard Template Library's.
Possible future ideas for improvement
- RSS description using the index entry's summary.
- Code syntax highlighter.
- Tags inside posts converted to hyperlinks to their respective category indices.
- Tags with icon mapping injection (icons alongside tag names).
- Auto Table-of-Contents based on headings inside post.
9. Repository links

